Sora:探索大型视觉模型的前世今生、技术内核及未来趋势 [译](下)
](https://soragenerated.video/uploadfile/2024/0229/f38a1d0d658aabe.jpg)
- Sora 教程
- by 宝玉
Sora Generated Video
摘要
Sora,一款由 OpenAI 在 2024 年 2 月推出的创新性文转视频生成式 AI 模型,能够依据文字说明,创作出既真实又富有想象力的场景视频,展现了其在模拟现实世界方面的巨大潜能。本文基于公开技术文档和逆向工程分析,全面审视了 Sora 背后的技术背景、应用场景、当前面临的挑战以及文转视频 AI 技术的未来发展方向。文章首先回顾了 Sora 的开发历程,探索了支撑这一“数字世界构建者”的关键技术。接着,我们详细探讨了 Sora 在电影制作、教育、市场营销等多个领域内的应用潜力及其可能带来的影响。文章还深入讨论了为实现 Sora 的广泛应用需克服的主要挑战,例如保证视频生成的安全性和公正性。最后,我们展望了 Sora 乃至整个视频生成模型技术未来的发展趋势,以及这些技术进步如何开创人机互动的新方式,进而提升视频创作的效率和创新性。 Sora Generated Videos
Sora Generated Video
Sora Generated Video
Sora Videos
 图 1:Sora —— AI 视觉生成的重大突破。
图 1:Sora —— AI 视觉生成的重大突破。
Sora Generated Video
Sora Generated Video
4 应用领域
随着 Sora 这类视频扩散模型成为尖端技术,它们在各个研究领域和行业的应用正迅速扩展。这项技术的潜力远不止于视频制作,它还能在自动化内容生成、复杂决策过程等任务中发挥变革性作用。本节我们将深入探索视频扩散模型当前的应用情况,并重点介绍 Sora 如何不仅展现了其强大能力,而且彻底改变了我们解决复杂问题的方式。我们旨在展现这些技术在实际应用场景中的广泛前景(参见图 18)。
Sora Videos
Sora Videos
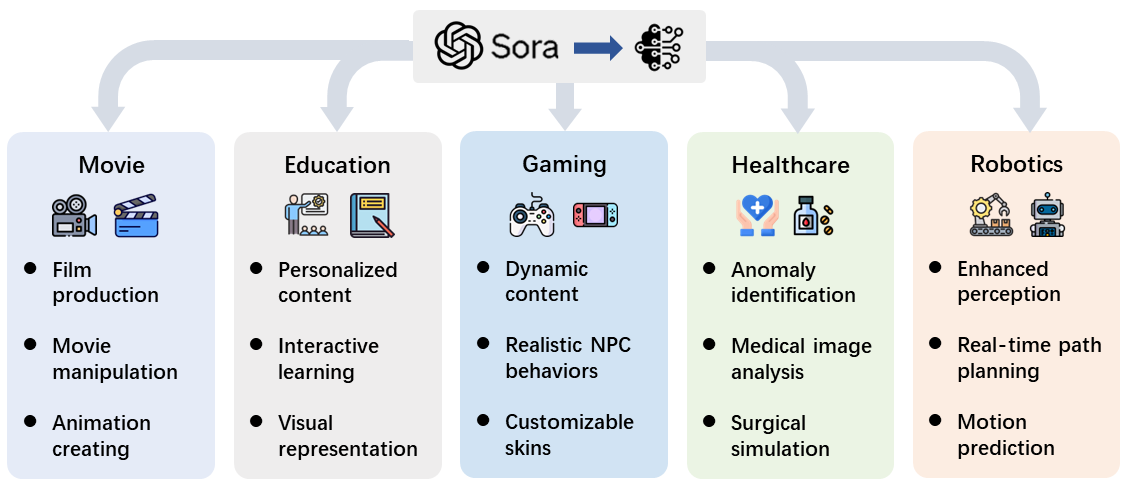 图 18: Sora 的应用案例。
图 18: Sora 的应用案例。
Sora Generated Video
Sora Videos
4.1 电影产业
传统电影制作是一个费时费力且成本高昂的过程,往往需要几十年的时间、先进设备和巨额投资。但现在,随着高级视频生成技术的出现,电影制作迎来了新纪元:通过简单的文本输入就能自动生成电影,这一梦想正在成为现实。研究人员利用视频生成模型拓展到电影制作领域,开创了电影生成的新篇章。例如,MovieFactory [133] 利用扩散模型根据 ChatGPT [89] 生成的精细剧本生成电影风格的视频,标志着技术上的一大进步。随后,MobileVidFactory [134] 能够仅凭用户提供的简文本自动创作竖屏移动视频。Vlogger [135] 让用户能以此技术创作出一分钟长的视频日志。Sora 轻松生成吸引人电影内容的能力,预示着电影制作民主化的新时代。这展现了一个未来景象,任何人都有机会成为电影制作人,极大降低了进入电影界的门槛,并引入了一种新的电影制作维度,将传统叙述与 AI 驱动的创意完美融合。这些技术不仅简化了电影制作过程,还有望彻底改变电影制作领域的面貌,使其更加开放、多样化,更好地适应观众不断变化的偏好和分发渠道的发展。 Sora Videos
4.2 教育革新
长期以来,教育领域的内容主要由静态资源构成,虽然这些资源具有一定的价值,但它们往往无法满足当前学生的多元化需求和学习方式。视频扩散模型作为教育革命的先锋,开创了定制化和活化教育材料的新篇章,极大地提高了学习者的参与度和理解能力。这些尖端技术让教育工作者能够把文字描述或课程大纲转换成充满活力、吸引人的视频内容,这些内容根据每个学生的独特风格和兴趣量身定制 [参考资料: 136,137,138,139]。此外,图像至视频的编辑技巧 [参考资料: 140,141,142] 为将静态教育资源变为互动视频提供了创新方法,满足了各种学习偏好,有望进一步提升学生的参与感。将这些模型融入教育内容的创作中,教师们可以就各种主题制作视频,让复杂的概念变得更加通俗易懂,为学生们带来吸引力。使用 Sora 来颠覆传统教育领域,展现了这些技术改变游戏规则的潜力。这种向个性化、动态教育内容的转变,标志着教育领域新纪元的到来。 Sora Generated Video
4.3 游戏行业
游戏产业始终在寻找方法,以突破真实感和沉浸体验的边界。然而,传统的游戏开发往往受限于预设的环境和剧本事件。现在,利用扩散模型实时生成的动态高清视频内容和逼真音效,有望突破这些限制。这为游戏开发者们开辟了新天地,使他们能够创造出随玩家行为和游戏事件自然变化的游戏环境 [143, 144]。这包括能够即时生成变化的天气、变幻的景观,乃至于创造全新的游戏场景,让游戏世界变得更加生动和反应灵敏。有些技术 [145, 146] 还能根据视频输入生成真实的碰撞声音,提升游戏的音效体验。整合了 Sora 技术的游戏领域,能够创造出前所未有的沉浸式体验,极大地吸引玩家。这不仅将改变游戏的开发和玩法方式,还将开启讲故事、互动和沉浸体验的新篇章。
Sora Videos
4.4 医疗保健
在医疗保健领域,尽管主要强调创造能力,视频扩散模型在理解和生成复杂视频序列方面的能力,使其特别适合于识别身体内部的动态变化,如细胞早期的自我消亡、皮肤病变的发展以及不规则的人体运动 [147, 148, 149]。这对早期发现疾病并采取干预措施至关重要。此外,像 MedSegDiff-V2 这样的模型 [150, 151] 利用变换器技术,以空前的精确度进行医学图像分割,使医生可以更准确地识别出各种成像技术中的关键区域。通过将 Sora 技术融入临床实践,不仅可以优化诊断流程,还可以根据精确的医学成像分析,为患者提供定制化的治疗方案。然而,技术的融合也带来了挑战,包括必须建立强有力的数据隐私保护措施,并在医疗实践中考虑伦理问题。
Sora Videos
4.5 机器人
在机器人领域,视频扩散模型正开启一个新篇章,它们不仅能创造和理解复杂的视频内容,从而极大地提升机器人的感知能力[152, 153],还能够在决策制定上发挥关键作用[154-156]。这项技术让机器人拥有了前所未有的互动及执行复杂任务的能力。通过引入大规模的扩散模型,我们看到了机器人视觉和理解能力的巨大提升潜力[152]。例如,现在的机器人可以通过“潜码扩散模型”接收语言指令来预测视频中的动作结果,这意味着它们能够更好地理解和完成任务[157]。此外,利用视频扩散模型创造出的高度逼真的视频序列,解决了机器人研究依赖模拟环境的局限性,为机器人提供了丰富多样的训练场景,克服了真实世界数据不足的问题[158, 159]。我们认为,将像 Sora 这样的尖端技术融入机器人学,将会带来革命性的进展。利用 Sora 的强大功能,机器人学的未来将实现空前的飞跃,使得机器人能够更自然地与周围环境互动和导航。
5 讨论
Sora 展现了其对人类复杂指令的精确理解和执行能力,特别擅长创作设置在精心布置的场景中、涵盖多种角色的细节丰富的视频。其最引人注目的特点之一是能够生成长达一分钟的视频,并保持始终如一且吸引人的叙事。这在先前主要关注制作更短视频的尝试中是一个重大进步,因为 Sora 的视频不仅叙事流畅,还能从头到尾维持视觉连贯性。此外,Sora 能创造出描绘复杂动作和互动的长视频,突破了早期模型仅能处理短视频和基础图像的局限。这一进展是 AI 驱动创意工具的一大飞跃,让用户有能力将文本故事转换为具有前所未有的细节和复杂度的生动视频。
Sora Generated Videos
5.1 局限性
面对物理真实性的挑战,Sora 作为一个仿真平台,在准确再现复杂情境方面存在一些局限。其中最显著的问题是它在处理复杂场景时对物理规则的应用不一致,有时候无法准确模拟出因果关系的特定例子。比如,吃掉一块饼干可能不会留下明显的咬痕,这种情况反映了系统偶尔会偏离物理的合理性。这一问题也影响到了运动的模拟,Sora 在模拟运动时,有时会产生与现实物理不符的动作,比如物体的不自然变形或是椅子这类刚体结构的不正确模拟,导致了不现实的物理互动。在模拟物体和角色之间复杂的相互作用时,问题更加明显,偶尔还会产生一些更倾向于幽默的结果。 Sora Videos
空间和时间方面的复杂性也是一个挑战。Sora 有时会误解有关物体和角色在场景中的放置或排列的指令,造成方向上的混淆(比如将左和右弄反)。同时,它在维持事件发生的时间顺序上也面临挑战,尤其是在遵循特定的摄影机移动或场景顺序时,可能会偏离原计划的时间线。在涉及许多角色或元素的复杂场景中,Sora 偶尔会加入一些与场景无关的动物或人物,这种情况可能会大幅改变场景原本的设想和氛围,偏离预定的叙事或视觉布局。这不仅影响了模型再现特定场景或叙事的准确性,也影响了其产出内容与用户期望及内容连贯性紧密对齐的可靠性。 Sora Generated Video
在人机交互(HCI)方面,尽管Sora 在视频生成领域展现了潜力,但它在 HCI 方面存在显著的限制。这些限制主要体现在用户与系统交互的连贯性和效率上,尤其是在对生成的内容进行详细的修改或优化时。例如,用户可能难以精确地指定或调整视频中特定元素的展示,如动作的细节和场景的过渡。此外,Sora 在理解复杂的语言指令或把握细微的语义差异方面也显示出限制,可能导致视频内容无法完全满足用户的期望或需求。这些问题限制了 Sora 在视频编辑和增强方面的应用潜力,也影响了用户体验的总体满意度。 Sora Generated Videos
使用限制方面,OpenAI 对公众开放 Sora 的具体上线时间持谨慎态度,强调在进行广泛推广前,需要确保安全性和准备工作充分。这意味着,在安全、隐私保护及内容审查等方面,Sora 还需经过进一步的完善和测试。目前,Sora 生成的视频最长只能达到一分钟,根据已发布案例,多数视频仅有数十秒的长度。这一局限性使其难以应用于需要展示较长内容的场合,如详尽的教程视频或深入的故事讲述,从而影响了 Sora 在内容创作上的灵活度。 Sora Generated Videos
5.2 机遇
在学术界,OpenAI 推出 Sora 是向着鼓励AI社区更深层次探索文本到视频模型、并利用扩散及变换器技术的战略转型的一大步。此举意在引导关注点转向利用文本描述直接创造出复杂细腻视频内容的潜能,这一领域的探索预示着内容创作、叙事及信息共享方式的革命性变革。此外,Sora 在其原生尺寸数据上的训练方法,与传统的缩放或裁剪相比,为学术界提供了新的启示,突出了使用未修改数据集的优势,为生成更先进模型铺平了道路。 Sora Videos
在行业方面,Sora 目前的能力展现了视频仿真技术发展的广阔前景,特别是在提高物理及数字领域真实度方面的潜力。通过文本描述能够创造出高度真实环境的能力,为内容创作领域带来了光明的未来,尤其是在游戏开发上,展示了用前所未有的简易度和精准度创造沉浸式世界的可能。此外,企业可以利用 Sora 快速适应市场变化,制作定制化的营销视频,这样不仅可以降低生产成本,还能提升广告的吸引力和效果。Sora 依靠文本描述独自生成高度真实视频的能力,有望彻底变革品牌与观众的互动方式,创造出既吸引人又引人入胜的视频,以新颖的方式展现其产品或服务的核心价值。 Sora Generated Videos
社会影响。(1)尽管利用文本转视频技术替代传统电影制作的想法还很遥远,但 Sora 和类似的平台对社交媒体内容创作具有革命性的影响力。现有的视频长度限制并未影响这些工具使高质量视频制作变得普及的潜力,让每个人都能够轻松制作引人入胜的内容,无需依赖昂贵的设备。这标志着内容创作者在 TikTok 和 Reels 等平台上被赋予了更大的权力,开启了创意和参与度的新纪元。(2)编剧和创意人员可以借助 Sora 把书面剧本变为视频,这不仅帮助他们更生动地展示和分享创意想法,还能制作短片和动画。将剧本转化为详细生动的视频,这一能力将彻底改变电影和动画前期制作的过程,预示着未来故事讲述者可能如何推介、发展和精炼他们的故事。这项技术为剧本开发引入了一种更动态、互动的方式,使创意想法可以即时可视化和评估,成为创新和合作的有力工具。(3)记者和新闻机构也可以通过 Sora 快速制作新闻报道或解说视频,让新闻内容更加鲜活和引人关注。这大大提高了新闻报道的传播范围和观众的参与程度。Sora 提供了一种强大的视觉叙事工具,通过模拟真实环境和场景,帮助记者以先前难以实现或成本高昂的视频形式讲述复杂的故事。综上所述,Sora 在推动营销、新闻和娱乐内容创作革命方面拥有巨大的潜力。 Sora Generated Videos
结论
我们综合回顾了 Sora,旨在帮助开发者和研究者深入了解其功能和相关研究。这项工作基于我们对已发布技术报告的调研和现有文献的逆向工程。随着 Sora 的 API 开放和更多细节的披露,我们将持续更新这篇论文。我们期待这篇综述能为开源研究社区提供价值,为未来社区共同开发 Sora 的开源版本铺平道路,实现在生成式人工智能(AIGC)时代的视频自动创作民主化。为此,我们欢迎各方的讨论、建议和合作。 Sora Generated Video
References
- [1]↑OpenAI, “Chatgpt: Get instant answers, find creative inspiration, learn something new..” https://openai.com/chatgpt, 2022.
- [2]↑OpenAI, “Gpt-4 technical report,” 2023.
- [3]↑OpenAI, “Sora: Creating video from text.” https://openai.com/sora, 2024.
- [4]↑W. Peebles and S. Xie, “Scalable diffusion models with transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4195–4205, 2023.
- [5]↑A. A. Efros and T. K. Leung, “Texture synthesis by non-parametric sampling,” in Proceedings of the seventh IEEE international conference on computer vision, vol. 2, pp. 1033–1038, IEEE, 1999.
- [6]↑P. S. Heckbert, “Survey of texture mapping,” IEEE computer graphics and applications, vol. 6, no. 11, pp. 56–67, 1986.
- [7]↑I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” arXiv, 2014.
- [8]↑D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [9]↑L. Dinh, D. Krueger, and Y. Bengio, “Nice: Non-linear independent components estimation,” arXiv preprint arXiv:1410.8516, 2014.
- [10]↑Y. Song and S. Ermon, “Generative modeling by estimating gradients of the data distribution,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [11]↑Y. Cao, S. Li, Y. Liu, Z. Yan, Y. Dai, P. S. Yu, and L. Sun, “A comprehensive survey of ai-generated content (aigc): A history of generative ai from gan to chatgpt,” arXiv preprint arXiv:2303.04226, 2023.
- [12]↑A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems (I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, eds.), vol. 30, Curran Associates, Inc., 2017.
- [13]↑J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [14]↑A. Radford, K. Narasimhan, T. Salimans, I. Sutskever, et al., “Improving language understanding by generative pre-training,” 2018.
- [15]↑A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [16]↑Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision, pp. 10012–10022, 2021.
- [17]↑O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pp. 234–241, Springer, 2015.
- [18]↑A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” 2021.
- [19]↑R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022.
- [20]↑M. AI, “Midjourney: Text to image with ai art generator.” https://www.midjourneyai.ai/en, 2023.
- [21]↑J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y. Guo, et al., “Improving image generation with better captions,” Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, vol. 2, p. 3, 2023.
- [22]↑P. AI, “Pika is the idea-to-video platform that sets your creativity in motion..” https://pika.art/home, 2023.
- [23]↑R. AI, “Gen-2: Gen-2: The next step forward for generative ai.” https://research.runwayml.com/gen2, 2023.
- [24]↑X. Zhai, A. Kolesnikov, N. Houlsby, and L. Beyer, “Scaling vision transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12104–12113, 2022.
- [25]↑M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. P. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin, et al., “Scaling vision transformers to 22 billion parameters,” in International Conference on Machine Learning, pp. 7480–7512, PMLR, 2023.
- [26]↑A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning, pp. 8748–8763, PMLR, 2021.
- [27]↑A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y. Levi, Z. English, V. Voleti, A. Letts, et al., “Stable video diffusion: Scaling latent video diffusion models to large datasets,” arXiv preprint arXiv:2311.15127, 2023.
- [28]↑U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Zhang, Q. Hu, H. Yang, O. Ashual, O. Gafni, D. Parikh, S. Gupta, and Y. Taigman, “Make-a-video: Text-to-video generation without text-video data,” 2022.
- [29]↑J. Ho, W. Chan, C. Saharia, J. Whang, R. Gao, A. Gritsenko, D. P. Kingma, B. Poole, M. Norouzi, D. J. Fleet, et al., “Imagen video: High definition video generation with diffusion models,” arXiv preprint arXiv:2210.02303, 2022.
- [30]↑R. Sutton, “The bitter lesson.” http://www.incompleteideas.net/IncIdeas/BitterLesson.html, March 2019.Accessed: Your Access Date Here.
- [31]↑S. Xie, “Take on sora technical report.” https://twitter.com/sainingxie/status/1758433676105310543, 2024.
- [32]↑A. Van Den Oord, O. Vinyals, et al., “Neural discrete representation learning,” Advances in neural information processing systems, vol. 30, 2017.
- [33]↑K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16000–16009, 2022.
- [34]↑S. Ge, S. Nah, G. Liu, T. Poon, A. Tao, B. Catanzaro, D. Jacobs, J.-B. Huang, M.-Y. Liu, and Y. Balaji, “Preserve your own correlation: A noise prior for video diffusion models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 22930–22941, 2023.
- [35]↑A. Sauer, D. Lorenz, A. Blattmann, and R. Rombach, “Adversarial diffusion distillation,” arXiv preprint arXiv:2311.17042, 2023.
- [36]↑A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis, “Align your latents: High-resolution video synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22563–22575, 2023.
- [37]↑M. Ryoo, A. Piergiovanni, A. Arnab, M. Dehghani, and A. Angelova, “Tokenlearner: Adaptive space-time tokenization for videos,” Advances in Neural Information Processing Systems, vol. 34, pp. 12786–12797, 2021.
- [38]↑A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić, and C. Schmid, “Vivit: A video vision transformer,” arXiv preprint arXiv:2103.15691, 2021.
- [39]↑L. Beyer, P. Izmailov, A. Kolesnikov, M. Caron, S. Kornblith, X. Zhai, M. Minderer, M. Tschannen, I. Alabdulmohsin, and F. Pavetic, “Flexivit: One model for all patch sizes,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14496–14506, 2023.
- [40]↑M. Dehghani, B. Mustafa, J. Djolonga, J. Heek, M. Minderer, M. Caron, A. Steiner, J. Puigcerver, R. Geirhos, I. M. Alabdulmohsin, et al., “Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [41]↑M. M. Krell, M. Kosec, S. P. Perez, and A. Fitzgibbon, “Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance,” arXiv preprint arXiv:2107.02027, 2021.
- [42]↑H. Yin, A. Vahdat, J. M. Alvarez, A. Mallya, J. Kautz, and P. Molchanov, “A-vit: Adaptive tokens for efficient vision transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10809–10818, 2022.
- [43]↑D. Bolya, C.-Y. Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your vit but faster,” in The Eleventh International Conference on Learning Representations, 2022.
- [44]↑M. Fayyaz, S. A. Koohpayegani, F. R. Jafari, S. Sengupta, H. R. V. Joze, E. Sommerlade, H. Pirsiavash, and J. Gall, “Adaptive token sampling for efficient vision transformers,” in European Conference on Computer Vision, pp. 396–414, Springer, 2022.
- [45]↑A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [46]↑G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?,” in ICML, vol. 2, p. 4, 2021.
- [47]↑L. Yu, J. Lezama, N. B. Gundavarapu, L. Versari, K. Sohn, D. Minnen, Y. Cheng, A. Gupta, X. Gu, A. G. Hauptmann, et al., “Language model beats diffusion–tokenizer is key to visual generation,” arXiv preprint arXiv:2310.05737, 2023.
- [48]↑N. Shazeer, “Fast transformer decoding: One write-head is all you need,” 2019.
- [49]↑J. Ainslie, J. Lee-Thorp, M. de Jong, Y. Zemlyanskiy, F. Lebrón, and S. Sanghai, “Gqa: Training generalized multi-query transformer models from multi-head checkpoints,” arXiv preprint arXiv:2305.13245, 2023.
- [50]↑A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” arXiv preprint arXiv:2312.00752, 2023.
- [51]↑J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” arXiv preprint arXiv:1503.03585, 2015.
- [52]↑J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in Neural Information Processing Systems, vol. 33, pp. 6840–6851, 2020.
- [53]↑Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” arXiv preprint arXiv:2011.13456, 2020.
- [54]↑F. Bao, S. Nie, K. Xue, Y. Cao, C. Li, H. Su, and J. Zhu, “All are worth words: A vit backbone for diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- [55]↑S. Gao, P. Zhou, M.-M. Cheng, and S. Yan, “Masked diffusion transformer is a strong image synthesizer,” arXiv preprint arXiv:2303.14389, 2023.
- [56]↑A. Hatamizadeh, J. Song, G. Liu, J. Kautz, and A. Vahdat, “Diffit: Diffusion vision transformers for image generation,” arXiv preprint arXiv:2312.02139, 2023.
- [57]↑J. Ho and T. Salimans, “Classifier-free diffusion guidance,” arXiv preprint arXiv:2207.12598, 2022.
- [58]↑T. Salimans and J. Ho, “Progressive distillation for fast sampling of diffusion models,” arXiv preprint arXiv:2202.00512, 2022.
- [59]↑J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, and T. Salimans, “Cascaded diffusion models for high fidelity image generation,” The Journal of Machine Learning Research, vol. 23, no. 1, pp. 2249–2281, 2022.
- [60]↑R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” 2021.
- [61]↑D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” arXiv preprint arXiv:2307.01952, 2023.
- [62]↑T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., “Language models are few-shot learners,” arXiv, 2020.
- [63]↑K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Conditional prompt learning for vision-language models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16816–16825, 2022.
- [64]↑V. Sanh, A. Webson, C. Raffel, S. H. Bach, L. Sutawika, Z. Alyafeai, A. Chaffin, A. Stiegler, T. L. Scao, A. Raja, et al., “Multitask prompted training enables zero-shot task generalization,” arXiv preprint arXiv:2110.08207, 2021.
- [65]↑J. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le, “Finetuned language models are zero-shot learners,” arXiv preprint arXiv:2109.01652, 2021.
- [66]↑L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al., “Training language models to follow instructions with human feedback,” Advances in Neural Information Processing Systems, vol. 35, pp. 27730–27744, 2022.
- [67]↑C. Jia, Y. Yang, Y. Xia, Y.-T. Chen, Z. Parekh, H. Pham, Q. Le, Y.-H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” in International conference on machine learning, pp. 4904–4916, PMLR, 2021.
- [68]↑J. Yu, Z. Wang, V. Vasudevan, L. Yeung, M. Seyedhosseini, and Y. Wu, “Coca: Contrastive captioners are image-text foundation models,” arXiv preprint arXiv:2205.01917, 2022.
- [69]↑S. Yan, T. Zhu, Z. Wang, Y. Cao, M. Zhang, S. Ghosh, Y. Wu, and J. Yu, “Video-text modeling with zero-shot transfer from contrastive captioners,” arXiv preprint arXiv:2212.04979, 2022.
- [70]↑H. Xu, Q. Ye, M. Yan, Y. Shi, J. Ye, Y. Xu, C. Li, B. Bi, Q. Qian, W. Wang, et al., “mplug-2: A modularized multi-modal foundation model across text, image and video,” arXiv preprint arXiv:2302.00402, 2023.
- [71]↑J. Wang, Z. Yang, X. Hu, L. Li, K. Lin, Z. Gan, Z. Liu, C. Liu, and L. Wang, “Git: A generative image-to-text transformer for vision and language,” arXiv preprint arXiv:2205.14100, 2022.
- [72]↑A. Yang, A. Miech, J. Sivic, I. Laptev, and C. Schmid, “Zero-shot video question answering via frozen bidirectional language models,” Advances in Neural Information Processing Systems, vol. 35, pp. 124–141, 2022.
- [73]↑Y. Li, “A practical survey on zero-shot prompt design for in-context learning,” in Proceedings of the Conference Recent Advances in Natural Language Processing - Large Language Models for Natural Language Processings, RANLP, INCOMA Ltd., Shoumen, BULGARIA, 2023.
- [74]↑B. Chen, Z. Zhang, N. Langrené, and S. Zhu, “Unleashing the potential of prompt engineering in large language models: a comprehensive review,” arXiv preprint arXiv:2310.14735, 2023.
- [75]↑S. Pitis, M. R. Zhang, A. Wang, and J. Ba, “Boosted prompt ensembles for large language models,” 2023.
- [76]↑Y. Hao, Z. Chi, L. Dong, and F. Wei, “Optimizing prompts for text-to-image generation,” 2023.
- [77]↑S. Huang, B. Gong, Y. Pan, J. Jiang, Y. Lv, Y. Li, and D. Wang, “Vop: Text-video co-operative prompt tuning for cross-modal retrieval,” 2023.
- [78]↑J. Z. Wu, Y. Ge, X. Wang, W. Lei, Y. Gu, Y. Shi, W. Hsu, Y. Shan, X. Qie, and M. Z. Shou, “Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation,” 2023.
- [79]↑T. Lüddecke and A. Ecker, “Image segmentation using text and image prompts,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7086–7096, June 2022.
- [80]↑X. Chen, Y. Wang, L. Zhang, S. Zhuang, X. Ma, J. Yu, Y. Wang, D. Lin, Y. Qiao, and Z. Liu, “Seine: Short-to-long video diffusion model for generative transition and prediction,” 2023.
- [81]↑H. Chen, Y. Zhang, X. Cun, M. Xia, X. Wang, C. Weng, and Y. Shan, “Videocrafter2: Overcoming data limitations for high-quality video diffusion models,” 2024.
- [82]↑T.-C. Wang, M.-Y. Liu, J.-Y. Zhu, G. Liu, A. Tao, J. Kautz, and B. Catanzaro, “Video-to-video synthesis,” 2018.
- [83]↑T.-C. Wang, M.-Y. Liu, A. Tao, G. Liu, J. Kautz, and B. Catanzaro, “Few-shot video-to-video synthesis,” 2019.
- [84]↑D. J. Zhang, D. Li, H. Le, M. Z. Shou, C. Xiong, and D. Sahoo, “Moonshot: Towards controllable video generation and editing with multimodal conditions,” 2024.
- [85]↑L. Zhuo, G. Wang, S. Li, W. Wu, and Z. Liu, “Fast-vid2vid: Spatial-temporal compression for video-to-video synthesis,” 2022.
- [86]↑P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,” 2021.
- [87]↑B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 3045–3059, 2021.
- [88]↑M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” in European Conference on Computer Vision, pp. 709–727, Springer, 2022.
- [89]↑OpenAI, “Introducing chatgpt,” 2023.
- [90]↑OpenAI, “Gpt-4v(ision) system card,” 2023.
- [91]↑Y. Huang and L. Sun, “Harnessing the power of chatgpt in fake news: An in-depth exploration in generation, detection and explanation,” 2023.
- [92]↑C. Chen and K. Shu, “Can llm-generated misinformation be detected?,” 2023.
- [93]↑Z. Liu, Y. Huang, X. Yu, L. Zhang, Z. Wu, C. Cao, H. Dai, L. Zhao, Y. Li, P. Shu, F. Zeng, L. Sun, W. Liu, D. Shen, Q. Li, T. Liu, D. Zhu, and X. Li, “Deid-gpt: Zero-shot medical text de-identification by gpt-4,” 2023.
- [94]↑J. Yao, X. Yi, X. Wang, Y. Gong, and X. Xie, “Value fulcra: Mapping large language models to the multidimensional spectrum of basic human values,” 2023.
- [95]↑Y. Huang, Q. Zhang, P. S. Y, and L. Sun, “Trustgpt: A benchmark for trustworthy and responsible large language models,” 2023.
- [96]↑L. Sun, Y. Huang, H. Wang, S. Wu, Q. Zhang, C. Gao, Y. Huang, W. Lyu, Y. Zhang, X. Li, Z. Liu, Y. Liu, Y. Wang, Z. Zhang, B. Kailkhura, C. Xiong, C. Xiao, C. Li, E. Xing, F. Huang, H. Liu, H. Ji, H. Wang, H. Zhang, H. Yao, M. Kellis, M. Zitnik, M. Jiang, M. Bansal, J. Zou, J. Pei, J. Liu, J. Gao, J. Han, J. Zhao, J. Tang, J. Wang, J. Mitchell, K. Shu, K. Xu, K.-W. Chang, L. He, L. Huang, M. Backes, N. Z. Gong, P. S. Yu, P.-Y. Chen, Q. Gu, R. Xu, R. Ying, S. Ji, S. Jana, T. Chen, T. Liu, T. Zhou, W. Wang, X. Li, X. Zhang, X. Wang, X. Xie, X. Chen, X. Wang, Y. Liu, Y. Ye, Y. Cao, Y. Chen, and Y. Zhao, “Trustllm: Trustworthiness in large language models,” 2024.
- [97]↑M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, D. Forsyth, and D. Hendrycks, “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,” 2024.
- [98]↑Y. Wang, H. Li, X. Han, P. Nakov, and T. Baldwin, “Do-not-answer: A dataset for evaluating safeguards in llms,” 2023.
- [99]↑B. Wang, W. Chen, H. Pei, C. Xie, M. Kang, C. Zhang, C. Xu, Z. Xiong, R. Dutta, R. Schaeffer, et al., “Decodingtrust: A comprehensive assessment of trustworthiness in gpt models,” arXiv preprint arXiv:2306.11698, 2023.
- [100]↑Z. Zhang, L. Lei, L. Wu, R. Sun, Y. Huang, C. Long, X. Liu, X. Lei, J. Tang, and M. Huang, “Safetybench: Evaluating the safety of large language models with multiple choice questions,” 2023.
- [101]↑X. Shen, Z. Chen, M. Backes, Y. Shen, and Y. Zhang, “" do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” arXiv preprint arXiv:2308.03825, 2023.
- [102]↑X. Liu, N. Xu, M. Chen, and C. Xiao, “Autodan: Generating stealthy jailbreak prompts on aligned large language models,” arXiv preprint arXiv:2310.04451, 2023.
- [103]↑S. Zhu, R. Zhang, B. An, G. Wu, J. Barrow, Z. Wang, F. Huang, A. Nenkova, and T. Sun, “Autodan: Interpretable gradient-based adversarial attacks on large language models,” 2023.
- [104]↑A. Zhou, B. Li, and H. Wang, “Robust prompt optimization for defending language models against jailbreaking attacks,” arXiv preprint arXiv:2401.17263, 2024.
- [105]↑X. Guo, F. Yu, H. Zhang, L. Qin, and B. Hu, “Cold-attack: Jailbreaking llms with stealthiness and controllability,” 2024.
- [106]↑A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How does llm safety training fail?,” arXiv preprint arXiv:2307.02483, 2023.
- [107]↑Z. Niu, H. Ren, X. Gao, G. Hua, and R. Jin, “Jailbreaking attack against multimodal large language model,” 2024.
- [108]↑H. Liu, W. Xue, Y. Chen, D. Chen, X. Zhao, K. Wang, L. Hou, R. Li, and W. Peng, “A survey on hallucination in large vision-language models,” 2024.
- [109]↑T. Guan, F. Liu, X. Wu, R. Xian, Z. Li, X. Liu, X. Wang, L. Chen, F. Huang, Y. Yacoob, D. Manocha, and T. Zhou, “Hallusionbench: An advanced diagnostic suite for entangled language hallucination & visual illusion in large vision-language models,” 2023.
- [110]↑Y. Li, Y. Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen, “Evaluating object hallucination in large vision-language models,” 2023.
- [111]↑Y. Huang, J. Shi, Y. Li, C. Fan, S. Wu, Q. Zhang, Y. Liu, P. Zhou, Y. Wan, N. Z. Gong, et al., “Metatool benchmark for large language models: Deciding whether to use tools and which to use,” arXiv preprint arXiv:2310.03128, 2023.
- [112]↑F. Liu, K. Lin, L. Li, J. Wang, Y. Yacoob, and L. Wang, “Mitigating hallucination in large multi-modal models via robust instruction tuning,” 2023.
- [113]↑L. Wang, J. He, S. Li, N. Liu, and E.-P. Lim, “Mitigating fine-grained hallucination by fine-tuning large vision-language models with caption rewrites,” in International Conference on Multimedia Modeling, pp. 32–45, Springer, 2024.
- [114]↑Y. Zhou, C. Cui, J. Yoon, L. Zhang, Z. Deng, C. Finn, M. Bansal, and H. Yao, “Analyzing and mitigating object hallucination in large vision-language models,” arXiv preprint arXiv:2310.00754, 2023.
- [115]↑I. O. Gallegos, R. A. Rossi, J. Barrow, M. M. Tanjim, S. Kim, F. Dernoncourt, T. Yu, R. Zhang, and N. K. Ahmed, “Bias and fairness in large language models: A survey,” arXiv preprint arXiv:2309.00770, 2023.
- [116]↑J. Zhang, K. Bao, Y. Zhang, W. Wang, F. Feng, and X. He, “Is chatgpt fair for recommendation? evaluating fairness in large language model recommendation,” arXiv preprint arXiv:2305.07609, 2023.
- [117]↑Y. Liang, L. Cheng, A. Payani, and K. Shu, “Beyond detection: Unveiling fairness vulnerabilities in abusive language models,” 2023.
- [118]↑F. Friedrich, P. Schramowski, M. Brack, L. Struppek, D. Hintersdorf, S. Luccioni, and K. Kersting, “Fair diffusion: Instructing text-to-image generation models on fairness,” arXiv preprint arXiv:2302.10893, 2023.
- [119]↑R. Liu, C. Jia, J. Wei, G. Xu, L. Wang, and S. Vosoughi, “Mitigating political bias in language models through reinforced calibration,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 14857–14866, May 2021.
- [120]↑R. K. Mahabadi, Y. Belinkov, and J. Henderson, “End-to-end bias mitigation by modelling biases in corpora,” 2020.
- [121]↑N. Mireshghallah, H. Kim, X. Zhou, Y. Tsvetkov, M. Sap, R. Shokri, and Y. Choi, “Can llms keep a secret? testing privacy implications of language models via contextual integrity theory,” arXiv preprint arXiv:2310.17884, 2023.
- [122]↑R. Plant, V. Giuffrida, and D. Gkatzia, “You are what you write: Preserving privacy in the era of large language models,” arXiv preprint arXiv:2204.09391, 2022.
- [123]↑H. Li, Y. Chen, J. Luo, Y. Kang, X. Zhang, Q. Hu, C. Chan, and Y. Song, “Privacy in large language models: Attacks, defenses and future directions,” 2023.
- [124]↑R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, E. Brynjolfsson, S. Buch, D. Card, R. Castellon, N. Chatterji, A. Chen, K. Creel, J. Q. Davis, D. Demszky, C. Donahue, M. Doumbouya, E. Durmus, S. Ermon, J. Etchemendy, K. Ethayarajh, L. Fei-Fei, C. Finn, T. Gale, L. Gillespie, K. Goel, N. Goodman, S. Grossman, N. Guha, T. Hashimoto, P. Henderson, J. Hewitt, D. E. Ho, J. Hong, K. Hsu, J. Huang, T. Icard, S. Jain, D. Jurafsky, P. Kalluri, S. Karamcheti, G. Keeling, F. Khani, O. Khattab, P. W. Koh, M. Krass, R. Krishna, R. Kuditipudi, A. Kumar, F. Ladhak, M. Lee, T. Lee, J. Leskovec, I. Levent, X. L. Li, X. Li, T. Ma, A. Malik, C. D. Manning, S. Mirchandani, E. Mitchell, Z. Munyikwa, S. Nair, A. Narayan, D. Narayanan, B. Newman, A. Nie, J. C. Niebles, H. Nilforoshan, J. Nyarko, G. Ogut, L. Orr, I. Papadimitriou, J. S. Park, C. Piech, E. Portelance, C. Potts, A. Raghunathan, R. Reich, H. Ren, F. Rong, Y. Roohani, C. Ruiz, J. Ryan, C. Ré, D. Sadigh, S. Sagawa, K. Santhanam, A. Shih, K. Srinivasan, A. Tamkin, R. Taori, A. W. Thomas, F. Tramèr, R. E. Wang, W. Wang, B. Wu, J. Wu, Y. Wu, S. M. Xie, M. Yasunaga, J. You, M. Zaharia, M. Zhang, T. Zhang, X. Zhang, Y. Zhang, L. Zheng, K. Zhou, and P. Liang, “On the opportunities and risks of foundation models,” 2022.
- [125]↑T. Shen, R. Jin, Y. Huang, C. Liu, W. Dong, Z. Guo, X. Wu, Y. Liu, and D. Xiong, “Large language model alignment: A survey,” arXiv preprint arXiv:2309.15025, 2023.
- [126]↑X. Liu, X. Lei, S. Wang, Y. Huang, Z. Feng, B. Wen, J. Cheng, P. Ke, Y. Xu, W. L. Tam, X. Zhang, L. Sun, H. Wang, J. Zhang, M. Huang, Y. Dong, and J. Tang, “Alignbench: Benchmarking chinese alignment of large language models,” 2023.
- [127]↑P. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” 2023.
- [128]↑T. Yu, Y. Yao, H. Zhang, T. He, Y. Han, G. Cui, J. Hu, Z. Liu, H.-T. Zheng, M. Sun, and T.-S. Chua, “Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback,” 2023.
- [129]↑M. S. Jahan and M. Oussalah, “A systematic review of hate speech automatic detection using natural language processing.,” Neurocomputing, p. 126232, 2023.
- [130]↑OpenAI, “Sora safety.” https://openai.com/sora#safety, 2024.
- [131]↑Z. Fei, X. Shen, D. Zhu, F. Zhou, Z. Han, S. Zhang, K. Chen, Z. Shen, and J. Ge, “Lawbench: Benchmarking legal knowledge of large language models,” arXiv preprint arXiv:2309.16289, 2023.
- [132]↑Y. Li, Y. Huang, Y. Lin, S. Wu, Y. Wan, and L. Sun, “I think, therefore i am: Benchmarking awareness of large language models using awarebench,” 2024.
- [133]↑J. Zhu, H. Yang, H. He, W. Wang, Z. Tuo, W.-H. Cheng, L. Gao, J. Song, and J. Fu, “Moviefactory: Automatic movie creation from text using large generative models for language and images,” arXiv preprint arXiv:2306.07257, 2023.
- [134]↑J. Zhu, H. Yang, W. Wang, H. He, Z. Tuo, Y. Yu, W.-H. Cheng, L. Gao, J. Song, J. Fu, et al., “Mobilevidfactory: Automatic diffusion-based social media video generation for mobile devices from text,” in Proceedings of the 31st ACM International Conference on Multimedia, pp. 9371–9373, 2023.
- [135]↑S. Zhuang, K. Li, X. Chen, Y. Wang, Z. Liu, Y. Qiao, and Y. Wang, “Vlogger: Make your dream a vlog,” arXiv preprint arXiv:2401.09414, 2024.
- [136]↑R. Feng, W. Weng, Y. Wang, Y. Yuan, J. Bao, C. Luo, Z. Chen, and B. Guo, “Ccedit: Creative and controllable video editing via diffusion models,” arXiv preprint arXiv:2309.16496, 2023.
- [137]↑J. Xing, M. Xia, Y. Liu, Y. Zhang, Y. Zhang, Y. He, H. Liu, H. Chen, X. Cun, X. Wang, et al., “Make-your-video: Customized video generation using textual and structural guidance,” arXiv preprint arXiv:2306.00943, 2023.
- [138]↑Y. Guo, C. Yang, A. Rao, Y. Wang, Y. Qiao, D. Lin, and B. Dai, “Animatediff: Animate your personalized text-to-image diffusion models without specific tuning,” arXiv preprint arXiv:2307.04725, 2023.
- [139]↑Y. He, M. Xia, H. Chen, X. Cun, Y. Gong, J. Xing, Y. Zhang, X. Wang, C. Weng, Y. Shan, et al., “Animate-a-story: Storytelling with retrieval-augmented video generation,” arXiv preprint arXiv:2307.06940, 2023.
- [140]↑H. Ni, C. Shi, K. Li, S. X. Huang, and M. R. Min, “Conditional image-to-video generation with latent flow diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18444–18455, 2023.
- [141]↑L. Hu, X. Gao, P. Zhang, K. Sun, B. Zhang, and L. Bo, “Animate anyone: Consistent and controllable image-to-video synthesis for character animation,” arXiv preprint arXiv:2311.17117, 2023.
- [142]↑Y. Hu, C. Luo, and Z. Chen, “Make it move: controllable image-to-video generation with text descriptions,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18219–18228, 2022.
- [143]↑K. Mei and V. Patel, “Vidm: Video implicit diffusion models,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, pp. 9117–9125, 2023.
- [144]↑S. Yu, K. Sohn, S. Kim, and J. Shin, “Video probabilistic diffusion models in projected latent space,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18456–18466, 2023.
- [145]↑K. Su, K. Qian, E. Shlizerman, A. Torralba, and C. Gan, “Physics-driven diffusion models for impact sound synthesis from videos,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9749–9759, 2023.
- [146]↑S. Li, W. Dong, Y. Zhang, F. Tang, C. Ma, O. Deussen, T.-Y. Lee, and C. Xu, “Dance-to-music generation with encoder-based textual inversion of diffusion models,” arXiv preprint arXiv:2401.17800, 2024.
- [147]↑A. Awasthi, J. Nizam, S. Zare, S. Ahmad, M. J. Montalvo, N. Varadarajan, B. Roysam, and H. V. Nguyen, “Video diffusion models for the apoptosis forcasting,” bioRxiv, pp. 2023–11, 2023.
- [148]↑A. Bozorgpour, Y. Sadegheih, A. Kazerouni, R. Azad, and D. Merhof, “Dermosegdiff: A boundary-aware segmentation diffusion model for skin lesion delineation,” in International Workshop on PRedictive Intelligence In MEdicine, pp. 146–158, Springer, 2023.
- [149]↑A. Flaborea, L. Collorone, G. M. D. di Melendugno, S. D’Arrigo, B. Prenkaj, and F. Galasso, “Multimodal motion conditioned diffusion model for skeleton-based video anomaly detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10318–10329, 2023.
- [150]↑J. Wu, R. Fu, H. Fang, Y. Zhang, and Y. Xu, “Medsegdiff-v2: Diffusion based medical image segmentation with transformer,” arXiv preprint arXiv:2301.11798, 2023.
- [151]↑G. J. Chowdary and Z. Yin, “Diffusion transformer u-net for medical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 622–631, Springer, 2023.
- [152]↑I. Kapelyukh, V. Vosylius, and E. Johns, “Dall-e-bot: Introducing web-scale diffusion models to robotics,” IEEE Robotics and Automation Letters, 2023.
- [153]↑W. Liu, T. Hermans, S. Chernova, and C. Paxton, “Structdiffusion: Object-centric diffusion for semantic rearrangement of novel objects,” in Workshop on Language and Robotics at CoRL 2022, 2022.
- [154]↑M. Janner, Y. Du, J. B. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” arXiv preprint arXiv:2205.09991, 2022.
- [155]↑A. Ajay, Y. Du, A. Gupta, J. Tenenbaum, T. Jaakkola, and P. Agrawal, “Is conditional generative modeling all you need for decision-making?,” arXiv preprint arXiv:2211.15657, 2022.
- [156]↑J. Carvalho, A. T. Le, M. Baierl, D. Koert, and J. Peters, “Motion planning diffusion: Learning and planning of robot motions with diffusion models,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1916–1923, IEEE, 2023.
- [157]↑X. Gu, C. Wen, J. Song, and Y. Gao, “Seer: Language instructed video prediction with latent diffusion models,” arXiv preprint arXiv:2303.14897, 2023.
- [158]↑Z. Chen, S. Kiami, A. Gupta, and V. Kumar, “Genaug: Retargeting behaviors to unseen situations via generative augmentation,” arXiv preprint arXiv:2302.06671, 2023.
- [159]↑Z. Mandi, H. Bharadhwaj, V. Moens, S. Song, A. Rajeswaran, and V. Kumar, “Cacti: A framework for scalable multi-task multi-scene visual imitation learning,” arXiv preprint arXiv:2212.05711, 2022.
- [160]↑T. Chen, L. Li, S. Saxena, G. Hinton, and D. J. Fleet, “A generalist framework for panoptic segmentation of images and videos,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 909–919, 2023.
- [161]↑W. Harvey, S. Naderiparizi, V. Masrani, C. Weilbach, and F. Wood, “Flexible diffusion modeling of long videos,” Advances in Neural Information Processing Systems, vol. 35, pp. 27953–27965, 2022.
- [162]↑A. Gupta, S. Tian, Y. Zhang, J. Wu, R. Martín-Martín, and L. Fei-Fei, “Maskvit: Masked visual pre-training for video prediction,” arXiv preprint arXiv:2206.11894, 2022.
- [163]↑W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang, “Cogvideo: Large-scale pretraining for text-to-video generation via transformers,” arXiv preprint arXiv:2205.15868, 2022.
- [164]↑U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Zhang, Q. Hu, H. Yang, O. Ashual, O. Gafni, et al., “Make-a-video: Text-to-video generation without text-video data,” arXiv preprint arXiv:2209.14792, 2022.
- [165]↑D. Zhou, W. Wang, H. Yan, W. Lv, Y. Zhu, and J. Feng, “Magicvideo: Efficient video generation with latent diffusion models,” arXiv preprint arXiv:2211.11018, 2022.
- [166]↑S. Ge, T. Hayes, H. Yang, X. Yin, G. Pang, D. Jacobs, J.-B. Huang, and D. Parikh, “Long video generation with time-agnostic vqgan and time-sensitive transformer,” in European Conference on Computer Vision, pp. 102–118, Springer, 2022.
- [167]↑R. Villegas, M. Babaeizadeh, P.-J. Kindermans, H. Moraldo, H. Zhang, M. T. Saffar, S. Castro, J. Kunze, and D. Erhan, “Phenaki: Variable length video generation from open domain textual description,” arXiv preprint arXiv:2210.02399, 2022.
- [168]↑P. Esser, J. Chiu, P. Atighehchian, J. Granskog, and A. Germanidis, “Structure and content-guided video synthesis with diffusion models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7346–7356, 2023.
- [169]↑L. Khachatryan, A. Movsisyan, V. Tadevosyan, R. Henschel, Z. Wang, S. Navasardyan, and H. Shi, “Text2video-zero: Text-to-image diffusion models are zero-shot video generators,” arXiv preprint arXiv:2303.13439, 2023.
- [170]↑Z. Luo, D. Chen, Y. Zhang, Y. Huang, L. Wang, Y. Shen, D. Zhao, J. Zhou, and T. Tan, “Videofusion: Decomposed diffusion models for high-quality video generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10209–10218, 2023.
- [171]↑A. Jabri, D. Fleet, and T. Chen, “Scalable adaptive computation for iterative generation,” arXiv preprint arXiv:2212.11972, 2022.
- [172]↑L. Lian, B. Shi, A. Yala, T. Darrell, and B. Li, “Llm-grounded video diffusion models,” arXiv preprint arXiv:2309.17444, 2023.
- [173]↑E. Molad, E. Horwitz, D. Valevski, A. R. Acha, Y. Matias, Y. Pritch, Y. Leviathan, and Y. Hoshen, “Dreamix: Video diffusion models are general video editors,” arXiv preprint arXiv:2302.01329, 2023.
- [174]↑J. H. Liew, H. Yan, J. Zhang, Z. Xu, and J. Feng, “Magicedit: High-fidelity and temporally coherent video editing,” arXiv preprint arXiv:2308.14749, 2023.
- [175]↑W. Chen, J. Wu, P. Xie, H. Wu, J. Li, X. Xia, X. Xiao, and L. Lin, “Control-a-video: Controllable text-to-video generation with diffusion models,” arXiv preprint arXiv:2305.13840, 2023.
- [176]↑W. Chai, X. Guo, G. Wang, and Y. Lu, “Stablevideo: Text-driven consistency-aware diffusion video editing,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 23040–23050, 2023.
- [177]↑S. Yang, Y. Zhou, Z. Liu, and C. C. Loy, “Rerender a video: Zero-shot text-guided video-to-video translation,” arXiv preprint arXiv:2306.07954, 2023.
- [178]↑D. Ceylan, C.-H. P. Huang, and N. J. Mitra, “Pix2video: Video editing using image diffusion,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 23206–23217, 2023.
- [179]↑B. Qin, J. Li, S. Tang, T.-S. Chua, and Y. Zhuang, “Instructvid2vid: Controllable video editing with natural language instructions,” arXiv preprint arXiv:2305.12328, 2023.
- [180]↑D. Liu, Q. Li, A.-D. Dinh, T. Jiang, M. Shah, and C. Xu, “Diffusion action segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10139–10149, 2023.
- [181]↑R. Feng, Y. Gao, T. H. E. Tse, X. Ma, and H. J. Chang, “Diffpose: Spatiotemporal diffusion model for video-based human pose estimation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14861–14872, 2023.
- [182]↑L. Yu, Y. Cheng, K. Sohn, J. Lezama, H. Zhang, H. Chang, A. G. Hauptmann, M.-H. Yang, Y. Hao, I. Essa, et al., “Magvit: Masked generative video transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10459–10469, 2023.
- [183]↑Z. Li, R. Tucker, N. Snavely, and A. Holynski, “Generative image dynamics,” arXiv preprint arXiv:2309.07906, 2023.
- [184]↑EasyWithAI, “Zeroscope - ai text-to-video model.” https://easywithai.com/ai-video-generators/zeroscope/, 2023.
- [185]↑R. Girdhar, M. Singh, A. Brown, Q. Duval, S. Azadi, S. S. Rambhatla, A. Shah, X. Yin, D. Parikh, and I. Misra, “Emu video: Factorizing text-to-video generation by explicit image conditioning,” arXiv preprint arXiv:2311.10709, 2023.
- [186]↑Y. Zeng, G. Wei, J. Zheng, J. Zou, Y. Wei, Y. Zhang, and H. Li, “Make pixels dance: High-dynamic video generation,” arXiv preprint arXiv:2311.10982, 2023.
- [187]↑A. Gupta, L. Yu, K. Sohn, X. Gu, M. Hahn, L. Fei-Fei, I. Essa, L. Jiang, and J. Lezama, “Photorealistic video generation with diffusion models,” arXiv preprint arXiv:2312.06662, 2023.
- [188]↑B. Wu, C.-Y. Chuang, X. Wang, Y. Jia, K. Krishnakumar, T. Xiao, F. Liang, L. Yu, and P. Vajda, “Fairy: Fast parallelized instruction-guided video-to-video synthesis,” arXiv preprint arXiv:2312.13834, 2023.
- [189]↑D. Kondratyuk, L. Yu, X. Gu, J. Lezama, J. Huang, R. Hornung, H. Adam, H. Akbari, Y. Alon, V. Birodkar, et al., “Videopoet: A large language model for zero-shot video generation,” arXiv preprint arXiv:2312.14125, 2023.
- [190]↑J. Wu, X. Li, C. Si, S. Zhou, J. Yang, J. Zhang, Y. Li, K. Chen, Y. Tong, Z. Liu, et al., “Towards language-driven video inpainting via multimodal large language models,” arXiv preprint arXiv:2401.10226, 2024.
- [191]↑O. Bar-Tal, H. Chefer, O. Tov, C. Herrmann, R. Paiss, S. Zada, A. Ephrat, J. Hur, Y. Li, T. Michaeli, et al., “Lumiere: A space-time diffusion model for video generation,” arXiv preprint arXiv:2401.12945, 2024.
Appendix ARelated Works
We show some related works about the video generation tasks in Table 1. Sora Generated Video
Table 1:Summary of Video Generation. Sora Generated Videos
| Sora Generated Video | Sora Generated Video | Sora Generated Video | Sora Generated Video | Sora Generated Video |
|---|---|---|---|---|
| Model name | Year | Backbone | Task | Group |
| Imagen Video[29] | 2022 | Diffusion | Generation | |
| Pix2Seq-D[160] | 2022 | Diffusion | Segmentation | Google Deepmind |
| FDM[161] | 2022 | Diffusion | Prediction | UBC |
| MaskViT[162] | 2022 | Masked Vision Models | Prediction | Stanford, Salesforce |
| CogVideo[163] | 2022 | Auto-regressive | Generation | THU |
| Make-a-video[164] | 2022 | Diffusion | Generation | Meta |
| MagicVideo[165] | 2022 | Diffusion | Generation | ByteDance |
| TATS[166] | 2022 | Auto-regressive | Generation | University of Maryland, Meta |
| Phenaki[167] | 2022 | Masked Vision Models | Generation | Google Brain |
| Gen-1[168] | 2023 | Diffusion | Generation, Editing | RunwayML |
| LFDM[140] | 2023 | Diffusion | Generation | PSU, UCSD |
| Text2video-Zero[169] | 2023 | Diffusion | Generation | Picsart |
| Video Fusion[170] | 2023 | Diffusion | Generation | USAC, Alibaba |
| PYoCo[34] | 2023 | Diffusion | Generation | Nvidia |
| Video LDM[36] | 2023 | Diffusion | Generation | University of Maryland, Nvidia |
| RIN[171] | 2023 | Diffusion | Generation | Google Brain |
| LVD[172] | 2023 | Diffusion | Generation | UCB |
| Dreamix[173] | 2023 | Diffusion | Editing | |
| MagicEdit[174] | 2023 | Diffusion | Editing | ByteDance |
| Control-A-Video[175] | 2023 | Diffusion | Editing | Sun Yat-Sen University |
| StableVideo[176] | 2023 | Diffusion | Editing | ZJU, MSRA |
| Tune-A-Video[78] | 2023 | Diffusion | Editing | NUS |
| Rerender-A-Video[177] | 2023 | Diffusion | Editing | NTU |
| Pix2Video[178] | 2023 | Diffusion | Editing | Adobe, UCL |
| InstructVid2Vid[179] | 2023 | Diffusion | Editing | ZJU |
| DiffAct[180] | 2023 | Diffusion | Action Detection | University of Sydney |
| DiffPose[181] | 2023 | Diffusion | Pose Estimation | Jilin University |
| MAGVIT[182] | 2023 | Masked Vision Models | Generation | |
| AnimateDiff[138] | 2023 | Diffusion | Generation | CUHK |
| MAGVIT V2[47] | 2023 | Masked Vision Models | Generation | |
| Generative Dynamics[183] | 2023 | Diffusion | Generation | |
| VideoCrafter[81] | 2023 | Diffusion | Generation | Tencent |
| Zeroscope[184] | 2023 | - | Generation | EasyWithAI |
| ModelScope | 2023 | - | Generation | Damo |
| Gen-2[23] | 2023 | - | Generation | RunwayML |
| Pika[22] | 2023 | - | Generation | Pika Labs |
| Emu Video[185] | 2023 | Diffusion | Generation | Meta |
| PixelDance[186] | 2023 | Diffusion | Generation | ByteDance |
| Stable Video Diffusion[27] | 2023 | Diffusion | Generation | Stability AI |
| W.A.L.T[187] | 2023 | Diffusion | Generation | Stanford, Google |
| Fairy[188] | 2023 | Diffusion | Generation, Editing | Meta |
| VideoPoet[189] | 2023 | Auto-regressive | Generation, Editing | |
| LGVI[190] | 2024 | Diffusion | Editing | PKU, NTU |
| Lumiere[191] | 2024 | Diffusion | Generation | |
| Sora[3] | 2024 | Diffusion | Generation, Editing | OpenAI Sora Generated Video |